新聞中心

連接器與互連設計,如何成為系統架構層級的決策
目前業界對 Vision AI 的討論,大多仍聚焦在模型層——鏡頭解析度、模型精度、推論延遲。這些指標有其參考價值,但它們所描述的,往往是整個系統中問題最少的部分。在實際部署環境中,系統故障通常發生在其他地方:在整個架構實體連接的方式上。
被忽視的路徑:從感測器到決策
拆解當今主流的 Vision AI 系統,可以梳理出一條清晰的資料路徑。
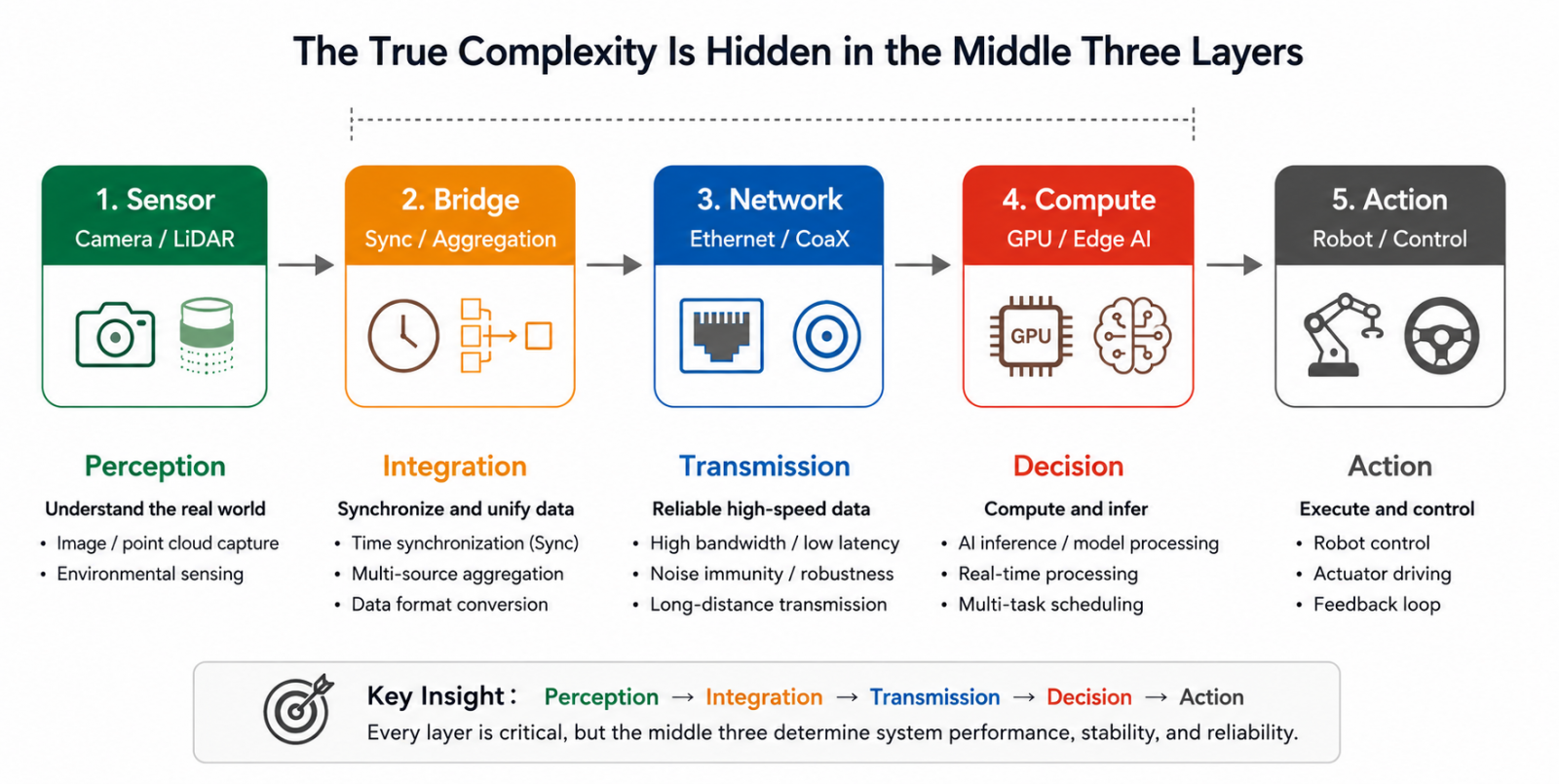
這條資料流程看似直觀,但絕大多數的複雜性都藏在中間層——感測器如何連接、資料如何匯聚、介面如何轉換,以及在資料抵達運算層之前如何維持穩定。過去被視為實作細節的問題,如今已成為關鍵的系統級約束。
這份複雜性也正在快速攀升。在 AMR 系統中,入門級室內導航平台可能需要約四個感測器;進階的室內外混合部署通常需要五至八個;重型戶外自主系統則可能擴展至八到十六個以上。
隨著感測器數量增加,橋接層的複雜度並非線性成長。每一條資料流都必須被正確同步、格式化、匯聚與傳輸。任何一個環節的失效,都可能導致無效的輸入送達運算層。
從 AI 到 Physical AI:系統必須真正動起來
這場轉變,也與 AI 本身的演進密切相關。
傳統 AI 系統大多專注於辨識與分類。當今的系統則必須在真實世界環境中持續運作——以即時的方式進行感知、決策與行動。
業界已開始以 Physical AI 一詞描述這場轉型。AI 不再只是運行在伺服器機房中的推論引擎,而是被嵌入必須持續感知環境、即時做出判斷、並可靠執行物理動作的機器之中。
一旦 AI 進入這種閉環架構,工程優先序也隨之改變。挑戰不再只是模型是否夠準確,而是:資料能否即時送達、系統響應能否保持穩定、不同模組之間能否真正協同運作。
當 AI 走入實體部署,基準測試數字的重要性,遠不及整體系統的實際行為表現。
真正的瓶頸在資料管線
一旦這些系統在真實環境中運行,瓶頸便會迅速浮現——而且大多存在於資料管線之中。
多路鏡頭串流可能讓匯聚頻寬達到飽和。感測器之間的時間戳記錯位,會導致融合演算法處理到無效資料。在特定條件下,GMSL 轉 Ethernet 的轉換可能引入難以預測的延遲抖動。在持續振動環境中,接觸電阻漂移會緩慢且間歇性地劣化訊號品質,且極難診斷。
時間同步是多感測器系統中最容易被低估的挑戰之一。鏡頭、LiDAR 與 IMU 各自運行在獨立時鐘上,若缺乏統一的時間基準,融合演算法便會接收到時間不一致的資料。
現代架構越來越依賴 1 PPS 訊號搭配 PTP 同步,將所有感測器時間戳記對齊至同一基準。然而,這需要橋接層具備專用硬體支援——單靠軟體補償,無法完全解決時序不一致的問題。
這些問題有一個共同特徵:極難透過軟體事後修復。
這也正是越來越多橋接與匯聚架構出現的原因——目的不在於增加功能,而在於確保整條資料路徑在真實操作條件下保持穩定且具確定性。
一個正在收斂的架構模式
縱觀不同系統的設計,一個清晰的架構收斂趨勢正在浮現。無論是 AMR、人形機器人,還是工業機械臂,先進系統越來越多地共享相同的骨幹架構:以 GMSL 或 MIPI 介面採集感測器資料、以 10GbE 及更高速規格的乙太網路作為系統骨幹、以 GPU 或邊緣 AI 模組執行推論,並以 EtherCAT 或 CANBus 驅動致動器與運動系統。
隨著邊緣 AI 系統朝更高感測器密度與更大即時工作負載擴展,記憶體頻寬與資料吞吐量也正成為邊緣運算平台的瓶頸。這意味著運算架構本身,正與資料管線並行演進。
高頻寬記憶體架構已成為下一代邊緣 AI 系統的組成要素。LPDDR5 CAMM2 等模組化高速記憶體介面,正開始出現在專為多鏡頭與高吞吐量工作負載設計的嵌入式 AI 及高效能邊緣運算平台上。
.png)
連接器設計是系統架構的一部分
過去,連接器的選型往往在設計週期的後期才被確認。只要介面相符、鎖固機構可接受、交期能配合,選型便被視為足夠。
這個假設正在瓦解。
隨著感測器密度提升,互連本身成為瓶頸。隨著傳輸速率攀升,訊號完整性直接影響整體系統穩定性。在高度整合的架構中,即使是微小的訊號干擾,也可能被放大成系統層級的穩定性問題。

在高速視覺傳輸領域,FAKRA 與 Mini FAKRA 已成為汽車與機器人視覺系統中,GMSL2 及序列化單端 LVDS 訊號經由單一高速同軸鏈路傳輸的標準互連方案。FAKRA 的 50Ω 阻抗設計與安全鎖固結構,針對高速同軸傳輸與振動密集環境進行最佳化;Mini FAKRA 則在不犧牲訊號完整性的前提下,縮小連接器尺寸,適用於多鏡頭、高密度系統架構。
焊接或組裝過程中引入的阻抗不連續性,在 6 Gbps 的 GMSL2 環境中會產生反射,直接影響鏈路穩定性。鎖固強度不足則會在振動環境下導致接觸電阻緩慢漂移,造成間歇性訊號劣化,且在已部署系統中的診斷成本極高。
這些故障通常在系統整合階段才會浮現,但根本原因往往可追溯至設計階段更早期的決策。
連接器設計因此不再只是零件選用問題——它已成為系統架構本身的一部分。
最終的差異化,或許不在 AI 本身
隨著 AI 模型能力持續收斂、運算資源愈趨商品化,差異化的重心正在轉移。
產業報告預測人形機器人的年複合成長率為 29%、AMR 為 14.4%、協作機器人則達 35.2%。這些數字背後,是一場更深層的轉變:系統正從實驗室驗證走向大規模量產部署。
在量產環境中,長期成功往往不取決於模型精度的些微提升或運算效能的邊際進步,而取決於系統能否長期保持穩定、能否可靠地規模化,以及能否在真實操作條件下持續運行。
這些挑戰並不顯眼——但卻遠比那些數字更貼近現實。
結語
隨著 Vision AI 系統在感測器數量與傳輸頻寬上持續擴展,從感測器連接、資料匯聚到邊緣運算架構的整條資料路徑,正成為系統設計本身的一部分,而非事後補足的細節。
FAKRA、Mini FAKRA 與下一代高速模組化介面,不再只是零件選擇,而是直接影響訊號完整性、系統穩定性與長期部署可靠性的架構決策。
對於正在評估下一代 Vision AI 連接與邊緣運算架構的工程團隊而言,所面臨的挑戰已超越 AI 模型本身。當感測器密度、頻寬、同步需求與即時運算負載同步攀升,系統穩定性已成為一個基礎設施層級的設計命題。
FAKRA、Mini FAKRA、HS-MTP,以及 LPDDR5 CAMM2 等模組化高速記憶體架構,都是這場朝向以資料為核心的邊緣 AI 系統設計轉型的組成部分。