
How Connector and Interconnect Design Became a System-Level Decision
Most discussions around Vision AI remain fixated on the model layer—camera resolution, inference accuracy, latency benchmarks. These metrics are legitimate, but they describe what is often the least problematic part of the system. In real-world deployments, failures tend to originate elsewhere: in how the architecture is physically connected together.
The Ignored Path: From Sensor to Decision
Breaking down today's mainstream Vision AI systems reveals a consistent data path.
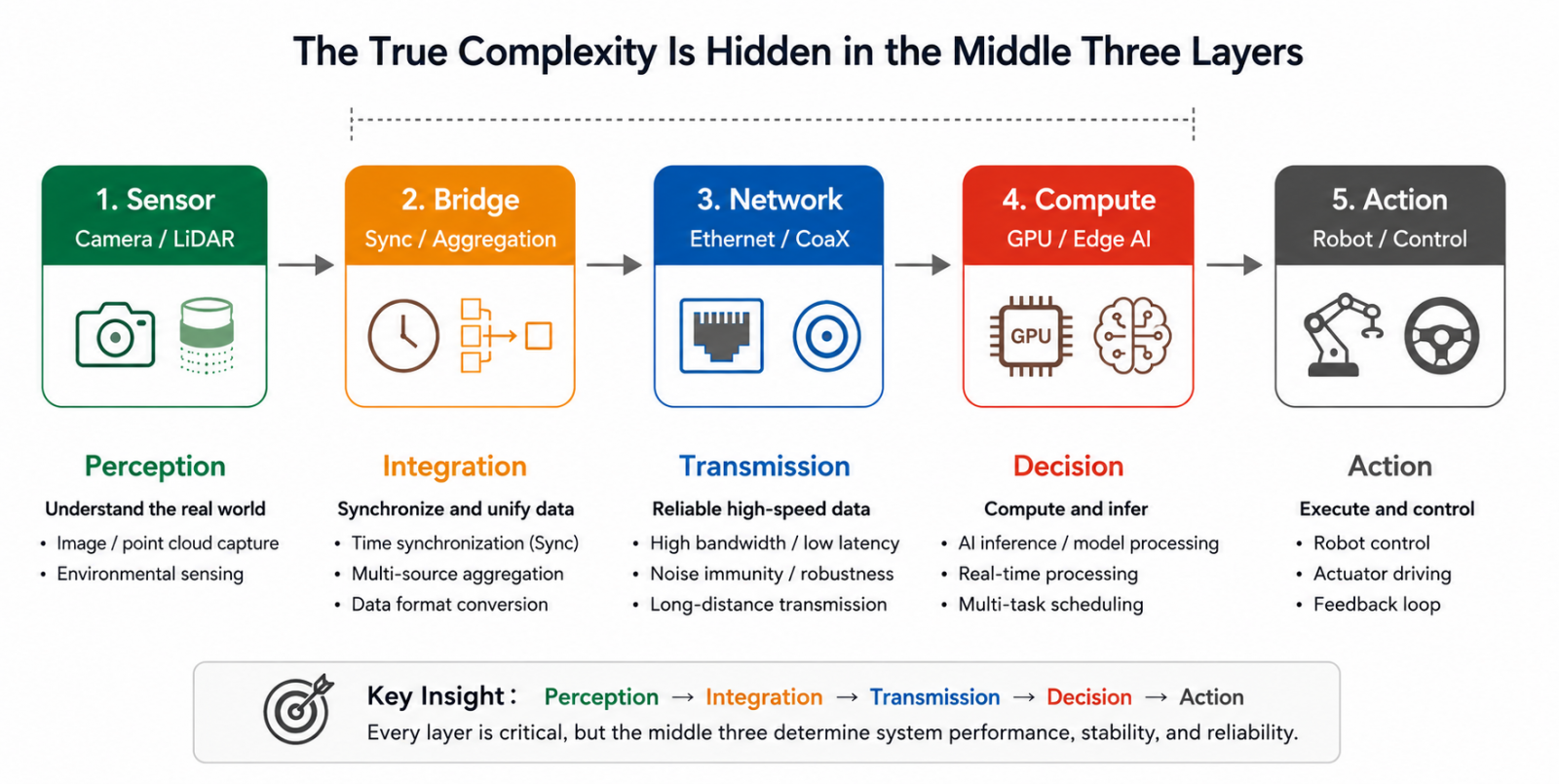
The flow appears straightforward, but the majority of engineering challenges are buried between sensor output and compute input—how raw data is collected, aggregated, converted, and kept stable before it ever reaches inference. What were once treated as implementation details have become critical system-level constraints.
That complexity is also scaling rapidly. In AMR platforms, entry-level indoor navigation systems may require around four sensors. Advanced indoor-outdoor deployments often demand five to eight. Heavy outdoor autonomous systems can scale to sixteen or more.
As sensor count grows, bridge-layer complexity does not scale linearly. Every data stream must be synchronized, formatted, aggregated, and transmitted correctly—and a failure at any single stage can corrupt the input before inference even begins.
From AI to Physical AI: The System Has to Actually Move
This architectural shift reflects a broader evolution in AI itself.
Traditional AI systems were primarily designed for recognition and classification—tasks that are largely stateless and tolerant of latency. Today's systems must operate continuously in dynamic real-world environments, perceiving, deciding, and acting in closed-loop real time.
The industry has converged on the term Physical AI to describe this transition. AI is no longer an inference engine running in a server rack with human operators in the loop. It is now embedded in machines that must sense their environment, make instantaneous decisions, and execute physical actions reliably—without interruption.
Once AI enters this closed-loop architecture, the engineering priorities shift accordingly. The question is no longer only whether the model is accurate. It becomes: does data arrive in time? Does the system maintain stable response under load? Do heterogeneous modules actually interoperate?
As AI moves into physical deployment, benchmark numbers matter less than end-to-end system behavior.
The Real Bottleneck Is in the Data Pipeline
Once these systems operate in real environments, bottlenecks surface quickly—and most of them live in the data pipeline, not the compute layer.
Multiple concurrent camera streams can saturate aggregation bandwidth. Timestamp misalignment between sensors causes fusion algorithms to process temporally inconsistent data. GMSL-to-Ethernet conversion can introduce unpredictable latency spikes under specific operating conditions. Under sustained vibration, contact resistance drift can degrade signal quality gradually and intermittently—making root cause diagnosis exceptionally difficult.
Time synchronization is one of the most underestimated challenges in multi-sensor system design. Cameras, LiDAR, and IMUs each operate on independent clocks. Without a unified timing reference, fusion algorithms receive inputs that are spatially coherent but temporally misaligned—an invisible failure mode that degrades system output without triggering obvious errors.
Modern architectures increasingly rely on 1 PPS signals combined with PTP (Precision Time Protocol) synchronization to align all sensor timestamps to a common reference. This, however, requires dedicated hardware support at the bridge layer. Software compensation alone cannot fully resolve timing inconsistency at the hardware level.
These failure modes share a defining characteristic: they are extremely difficult to address through software after the fact.
This is why purpose-built bridge and aggregation architectures are proliferating—not to add features, but to ensure the entire data path remains stable and deterministic under real operating conditions.
A Converging Architecture Pattern
Abstracting across different system designs, a clear architectural convergence is emerging. Whether in AMRs, humanoid robots, or industrial robotic arms, advanced Vision AI platforms are increasingly built around the same backbone: GMSL or MIPI interfaces for sensor data collection, 10GbE and beyond as the high-speed system backbone, GPU or edge AI modules for real-time inference, and EtherCAT or CANBus for actuator and motion control.
As edge AI systems scale toward higher sensor density and larger real-time workloads, memory bandwidth and data throughput are also emerging as compute-layer bottlenecks. Compute architecture is now evolving in parallel with the data pipeline—not independently of it.
High-bandwidth memory interfaces are becoming a core component of next-generation edge AI systems. Modular architectures such as LPDDR5 CAMM2 are beginning to appear in embedded AI and high-performance edge compute platforms purpose-built for multi-camera and high-throughput workloads.
.png)
Connector Design Is Part of the Architecture
Historically, connector selection was finalized late in the design cycle. If interfaces matched, locking mechanisms were acceptable, and lead times were manageable, the selection was considered adequate.
That assumption no longer holds.
As sensor density increases, interconnects themselves become bandwidth bottlenecks. As transmission speeds rise, signal integrity directly determines system stability. In tightly integrated architectures, even minor signal disturbances can propagate into system-level failures.

For high-speed vision transmission, FAKRA and Mini FAKRA have become standard interconnect solutions for GMSL2 and serialized single-ended LVDS signals over single high-speed coaxial links in automotive and robotics applications. FAKRA's 50Ω impedance design and secure locking structure are optimized for high-speed coaxial transmission and vibration-intensive environments. Mini FAKRA reduces form factor for multi-camera, high-density architectures without compromising signal integrity.
Impedance discontinuities introduced during soldering or assembly generate reflections in 6 Gbps GMSL2 environments that directly affect link stability. Insufficient locking strength leads to gradual contact resistance drift under vibration—producing intermittent signal degradation with very high diagnostic costs in deployed systems.
These failures typically surface during system integration. Their root causes, however, almost always originate in earlier design decisions.
Connector design is no longer a component selection problem. It has become part of the system architecture.
The Final Differentiator May Not Be the Model
As AI models continue converging in capability and compute becomes increasingly commoditized, competitive differentiation is shifting elsewhere.
Industry projections place humanoid robots at a 29% CAGR, AMRs at 14.4%, and collaborative robots at 35.2%. Behind these figures is a structural transition: systems are moving from controlled laboratory demonstrations into large-scale production deployment.
In production environments, long-term program success is rarely determined by marginal model accuracy gains or incremental compute improvements. It is determined by whether the system remains stable over time, scales reliably across units, and sustains deployment under real-world operating conditions.
These challenges are less visible in benchmark comparisons—but far closer to the realities of productization.
Conclusion
As Vision AI systems continue scaling in both sensor count and transmission bandwidth, the entire data path—from sensor connectivity and signal aggregation to edge compute architecture—is becoming a core element of system design, not an afterthought.
FAKRA, Mini FAKRA, and next-generation high-speed modular interfaces are no longer discrete component choices. They are architectural decisions that directly affect signal integrity, system stability, and long-term deployment reliability.
For engineering teams designing next-generation Vision AI platforms, the challenge is increasingly one of infrastructure. As sensor density, bandwidth requirements, synchronization constraints, and real-time compute demands scale together, system stability has become an infrastructure-level design problem—one that begins long before the first line of inference code is written.
FAKRA, Mini FAKRA, HS-MTP, and modular high-speed memory architectures such as LPDDR5 CAMM2 are all part of this broader transition toward data-centric edge AI system design.